ChatGPTのGPTsで実装するブランド表記統一チェックボット
当記事の要点▼
- ブランド名の表記ゆれ問題をGPTsで自動検出し、修正する必然性と効果を詳しく解説し導入メリットを提示
- GPTs編集画面からプロンプト設計・機能設定・ナレッジ登録までの構築5ステップを解説
- 情報漏洩防止や権限管理など、国内法準拠のセキュリティ対策と設定手順を具体的に示す方法を紹介
- 導入後30・60・90日でKPIを追跡しPDCAを回して、精度とROIを高める運用改善手法を紹介
こんにちは、FreedomBuildの駒田です。
もしあなたが、日々の業務でブランド表記の不一致に悩まされていたらどうでしょう。
社内資料や広告原稿で微妙に異なる名前表記が混在しているために、クライアントや上層部から修正を求められ、貴重な時間を無駄にしてしまうこともあるかもしれません。
手作業でのチェックは手間がかかり、見逃しが続出することも…。
こうした課題を解決するために活用できるのが、ChatGPTのGPTsを活用した「ブランド表記統一チェックボット」です。
本記事では、このGPTsを使ったチャットボットを導入するメリットや実装手順、運用までを詳しく解説します。
読了後には、あなたの組織で混在しているブランド名称や商標表記のばらつきを一掃し、ブランディング品質を大幅に向上させる方法が見えてくるはずです。
さっそく、その背景から見ていきましょう。
※ 記事の執筆にAIを使用しています。
急伸するAI活用の市場背景
企業がAI導入を加速させる流れは、この数年で一気に高まりました。
特に2023年にChatGPTが公開されて以降、AIに対する認知度とニーズはかつてないほど上昇し、日本企業も「AI時代に乗り遅れたくない」というモチベーションから多様な用途での導入を模索しています。
たとえば、帝国データバンクの調査(2023年)によれば、約60%以上の日本企業が生成AI導入を検討中であり、すでに導入済みと回答した企業も10%近くにのぼるという報告が出ているほどです。
一方で、「AIを使って何を改善すべきか、具体的にイメージできない」という声も決して少なくありません。
AIチャットボットを導入しても、FAQの自動応答しか使っていない企業もあり、十分な効果を得られていないケースも目立ちます。
AIの強みを引き出すには、業務課題を的確に絞り、その領域にフォーカスした専用ツールとして運用することが重要です。
日本特有の事情としては、高品質志向や情報セキュリティ意識が強く、社内でのAI活用にあたってガバナンスや法規への適合を非常に重視する文化があります。
さらに大企業だけでなく、中小企業やベンチャーでもAIを導入している例が増えつつあり、「限られたリソースをいかに効率よく使うか」という理由から導入に踏み切ることが多いようです。
実際、最新の市場予測データ(IDC Japan, 2023)では、日本の生成AI市場規模は2024年には1,016億円規模、2028年には8,028億円にまで拡大するとされています。
これはAIの認知度と導入ハードルが下がった証と言えるでしょう。
より具体的には、AIを使った自然言語処理による文書作成や、コード生成といった知的労働の効率化ニーズが高まっています。
こうした用途では単なるFAQ応答にとどまらず、企業独自のナレッジベースとの連携や、セキュリティを担保しながら機密文書を扱う仕組み作りが求められているのです。
そこで、ChatGPTのGPTs機能が注目されています。
GPTsとはChatGPT上で作成可能なカスタムAIモデルの一種で、GPT-4oをベースとしてユーザーが固有の運用ルールやナレッジファイルを付与し、専用のチャットボットを構築できる機能です。
企業がAIを導入する際に必要とされるクローズドな環境や特定用途特化の実装を行いやすく、セキュリティ面でも設定しやすいため注目度は高まり続けています。
今後は、ChatGPTのGPTsを使いこなし、社内データと連携して独自業務に即したチャットボットを作る取り組みが標準化するでしょう。
こうした流れを先取りできれば、日々の煩雑な作業を大幅に省力化しながら、バラツキのないブランドコミュニケーションを展開できる可能性があります。
では、次章では具体的な問題点を改めて整理し、なぜブランド表記を一本化するAIツールが求められるのか、深堀りしていきましょう。
国内AI需要の多様化
日本においてAI導入が多様化している要因の一つに、働き方改革や人材不足への対処があります。
カスタマーサポートや社内問い合わせをAIボットに任せる事例は急増し、24時間対応による顧客満足度向上を目指すケースも目立ちます。
これに加え、ナレッジマネジメントや資料作成の自動化分野にも関心が集まっています。
GPTの進化とビジネスインパクト
GPTは、自然言語の理解と生成に優れた大規模言語モデル。
特にGPT-4の登場以降、日本語の文脈理解や表現力が格段に向上しました。
複雑な業務指示を理解し、関連情報を照合しながら回答を出す能力を持つため、ドキュメントの校閲やテキスト生成、専門的な文章作成にも応用されています。
中小企業と大企業のギャップ
大企業は大規模導入で巨大な工数削減を期待する一方、中小企業は社内リソース不足を補う目的で導入を進める例が増えています。
どちらも人員の省力化という目的は共通ですが、必要なカスタマイズ度合いやデータの扱い方は異なるため、ベンダーが提供するAIサービスの選択基準も多様です。
期待されるブランディング統一
日本企業は、公式書類や広告・Webサイトなどでブランド表記の統一に非常に敏感です。
市場調査会社のレポートでも、企業イメージ向上に向けた表記ガイドラインの徹底が重要と繰り返し言及されており、実際にブランドの認知度と売上増に相関があるとの報告もあります。
今後はマーケティングやPR部門だけでなく、総務・法務部門からも「表記ミスの防止にAIを使いたい」といった要求が増えることが予想されています。
まとめると、急伸するAI市場のなかで、ChatGPTのGPTsを活用した業務特化ボットは大きな注目を浴びています。
その一例として「ブランド表記統一チェックボット」が有効なソリューションとなり得るわけです。
ブランド表記ゆえの混乱が進む理由
どの企業でもブランド表記の乱れは少なからず発生しているのではないでしょうか。
例えば、提案資料や社内マニュアル、広報資料などで「プロダクト名の一部が違っている」「商標マーク付きで書かないといけないのに、マークがついていない」などの事例が頻発することがあります。
課題の深刻度を数値化すると、たとえば大手証券会社が2024年に行った内部監査では、全社発行文書の約15%で「ブランド名の不適切な表記」があったことが確認されています。
中小企業でも似たケースは多く、担当者が認識しないうちに重大な商標権関連のトラブルを引き起こすリスクが潜んでいるのです。
ここでは、こうしたブランド表記の混乱がなぜ起きるのかを具体的に掘り下げてみましょう。
シーン別の「あるある」課題
- 社内稟議のフォーム表記がバラバラ
承認ワークフローにおいて各部署が独自テンプレートを使用しているため、ブランド名やサービス名が部署ごとに違う表記になっている。 - 広告代理店とのやり取りが複数社にまたがる
広告戦略を外部に委託する場合、複数社と同時並行でプロモーションを進めると、新商品名の仮称や表記ルールが伝わらず、正式版と混在してしまう。 - 多言語展開時のローカライズ表記
英語でのブランド名と日本語でのブランド名表記が整合しないまま資料が出回り、海外顧客から「どれが正式名なのか分からない」と問い合わせを受ける。
こうした現象は、さまざまな部署や外注先が関わるほど増幅していき、放置すれば企業のイメージダウンや法的リスクにも発展しうるのが厄介な点です。
原因の深掘り
ブランド表記の混乱は、単純に担当者がミスをしているだけではありません。
組織的に見た場合、以下のような構造的原因が絡み合っています。
- 表記ガイドラインの周知不足
新ブランドや子会社統合などで表記ルールが更新されても、現場まで情報が行き渡らない。 - 属人的な確認フロー
最終チェックを個人の校閲力に任せており、確認者が急ぎ対応すると見落としが発生する。 - ドキュメント分散管理
似たような書類が多数存在し、どのバージョンが公式か不透明になっている。 - AI活用をためらう文化
データ漏洩や誤変換に対する過剰な懸念から、校正にはまだ人力が最適と考える組織もある。
もしこのままの状況を放置すると、「失敗広告」として世間に晒される可能性もあり、ブランドそのものの価値が損なわれかねません。
また、社内での提出書類が度重なる修正で効率を下げ、担当者のモチベーション低下や業務負荷増大につながる危険もあります。
被害を受ける人たちの実態
たとえば営業チームの新人・山田さんは、クライアント提出用の資料に自社ブランド名を正しく入れるだけで30分以上を費やしています。
メールで送られてきた旧ロゴや旧表記のままテンプレートが使われていたり、部署によって「™」マークが要る・要らないの判断が違っていたりするためです。
上司に提出するたび「これ古い表記だよ」と突っ返される日々が続き、焦燥感と残業の増加に悩まされています。
放置リスクと既存施策の限界
放置すれば、ブランディング失敗による売上機会損失だけでなく、商標権の侵害といった法的リスクまで拡大する恐れがあります。
実際に、海外との取引で誤った登録商標を使ってしまい、数千万円の損害賠償請求を受けた例も報じられています。
もちろん、従来の校正ツールや人力チェックである程度は防げるものの、大量の文書を対象に、すべてを見逃しなくチェックするのは現実的に限界があります。
果たして、この「ブランド表記統一」問題をどう解決すべきなのか。
課題の根幹と緊急性
多くの企業で、ブランド表記の乱れは「些細な問題」と捉えられがちです。
しかし、実際には企業イメージに直結する重要なテーマであり、放置するほどブランドの信頼度に傷がつく結果になりかねません。
しかも、表記ゆれを根本的に防ぐには、全社員が意識を変える必要があり、一度や二度の指導だけで改善できるものでもないのです。
ここにこそ、AIの支援を得て自動かつ統合的なチェック体制を構築する必然性があるのです。
次章では、ChatGPTのGPTsがどのようにこの課題にアプローチし、具体的な成果をもたらすのかを詳しく説明します。
GPTsでブランド表記統一を実現する方法
前章で示したようなブランド表記の混乱は、従来の手動チェックやOfficeのスペルチェックではなかなか解消しづらい面があります。
たとえ管理部門がルールを整備しても、最終的には人の判断に頼らざるを得ず、表記ミスが漏れてしまうのが実情でした。
しかし、ChatGPTのGPTsを活用すれば、組織内でブランド表記を統一するための専用AIチャットボットを構築することができ、こうした悩みを一挙に解消しやすくなります。
ここではまず、GPTs活用のメリットや従来手法との比較を整理し、導入することで得られる具体的効果をイメージしていただきたいと思います。
従来手法とGPTs手法の比較
| 従来のブランド表記チェック手法 | GPTsを使ったブランド表記チェック |
|---|---|
| マニュアルやチェックリストを参照して人が確認 | AIが文脈を理解しながら自動チェック |
| カスタマイズが難しく、特殊用語や固有表記への対応に限界 | ナレッジファイルへ自社ルールを反映し、柔軟に拡張可能 |
| 最終的な精度は担当者の経験に依存 | GPT-4ベースの高度言語処理で表記ゆれを高精度に捕捉 |
| チェック頻度が多いと工数が膨大 | 短時間に大量ドキュメントをクロール・確認できる |
| セキュリティ面で外部ツールを敬遠しがち | GPTsならクラウドでもオンプレ環境でも選択肢あり |
上記のように、GPTsを使った方法では「文脈」や「固有名詞の由来」など、単なる単語検索では拾えない部分まで考慮しやすくなるのが大きな特長です。
さらに、ChatGPTと同等の自然な応答力を持つため、表記だけでなく関連するガイドラインの補足説明や根拠資料の参照なども同時に行うことが可能になります。
ブランド表記チェックボットのベネフィット
ブランド表記の統一をAIに任せることで、業務効率だけでなく組織全体の情報品質も向上します。
以下に、GPTsによるチェックボット導入の主要な利点を整理してみました。
- 時間削減
これまで担当者が何時間も費やしていた表記の確認作業をボットが自動化。段取りよく修正案を提示してくれるため、月に数十〜数百時間の工数削減が期待できます。 - 属人化解消
経験豊富な社員だけが知っている「正しい表記ルール」をAIに学習させることで、誰でも同じ品質の文章を作成できるようになります。退職や異動によるノウハウ消失を防ぐ効果も大きいです。 - 継続的学習
GPTsはナレッジファイルを更新すれば、すぐに新ブランドや最新規定を反映できます。常に最新情報を取り込み、表記ゆれをリアルタイムに補正してくれるのです。 - 他用途への横展開
一度GPTsを構築すれば、ブランド表記以外の用途にも拡張しやすい点は見逃せません。社員向けFAQやプロダクトQA、テクニカルサポートなど、多彩なチャットボットを追加で作る土台になります。
とある広告担当者の事例
広報担当の吉田さんは、新製品「Xprime™」のリリース告知文書を、社内の各部署に送ってから気づきました。
資料内では「XPrime」「Xprime(R)」など表記揺れが存在し、営業部やマーケ部から「どれが正しいのか」と質問が殺到。
手動で修正を行ううちに1週間が経過し、広告掲載や外部メディアへのプレスリリースが遅れてしまいました。
そこで吉田さんは、GPTsで作成した「ブランド表記統一チェックボット」を使い、まずはリリース文書をAIに入力したのです。
すると、Xprime™の正確な表記や商標マークの位置まで自動提案が一括で提示されました。
さらに誤った表記を検知した箇所にはコメント付きで修正理由が示されるため、短時間で資料を統一可能に。
結果として、余裕をもってプレスリリースを展開でき、外部への正確なブランド発信が実現しました。
想定される懸念と簡易回答
- 費用面が心配…
GPTsを作成するには有料プランのChatGPTアカウントが必要ですが、月20ドル課金で最小限スタートでき、PoC段階で費用対効果を確かめやすいのが利点です。 - セキュリティは大丈夫?
GPTsの編集画面で「モデル改善チェックOFF」を設定すれば、入力データが外部に学習利用されにくい環境を保てます。大企業であればチームプランのワークスペースを使い、権限管理を厳格にする例も増えています。 - 精度にばらつきが出ないか?
自社固有ルールをナレッジファイルに追加し、RAG(Retrieval-Augmented Generation)によって参照する仕組みを導入すれば、余計なハルシネーション(幻影回答)を抑えられます。
これらの懸念に対しては、次章の実装ステップでより具体的な対応策を解説していきます。
ぜひ合わせてお読みください。
実装手順を5ステップで組み立てる
ブランド表記統一チェックボットをChatGPTのGPTsで構築するプロセスは、大きく5つのステップに分けられます。
ここでは、設定画面へのアクセス方法から知識ファイルの活用、最終的なアクション設定までを一連の手順として解説します。
全体を俯瞰してから進めることで、導入時の混乱を最小限に抑えやすくなるでしょう。
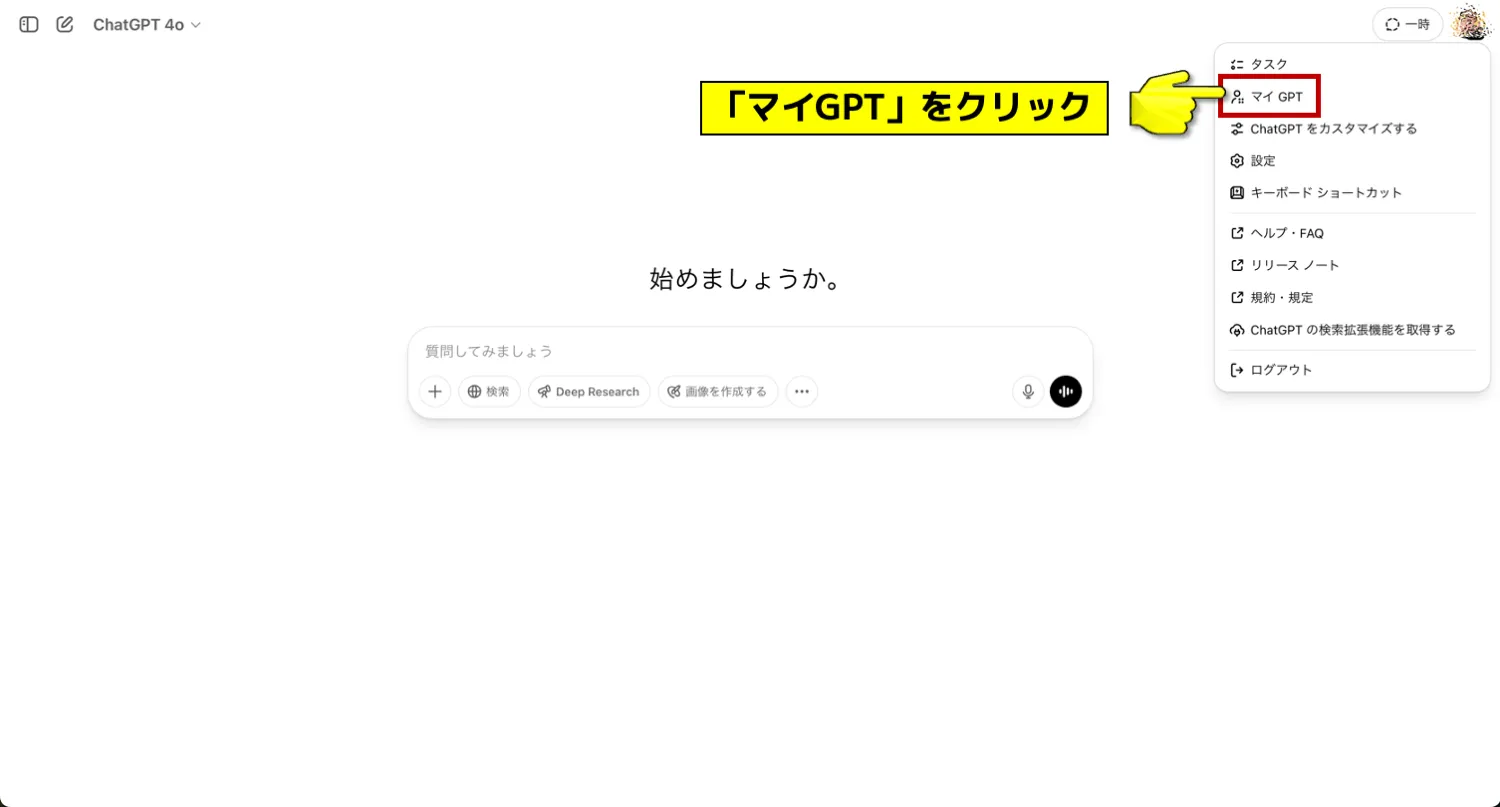
Step 1: GPTs編集画面にアクセスする
まずはGPTsの編集画面に入る必要があります。
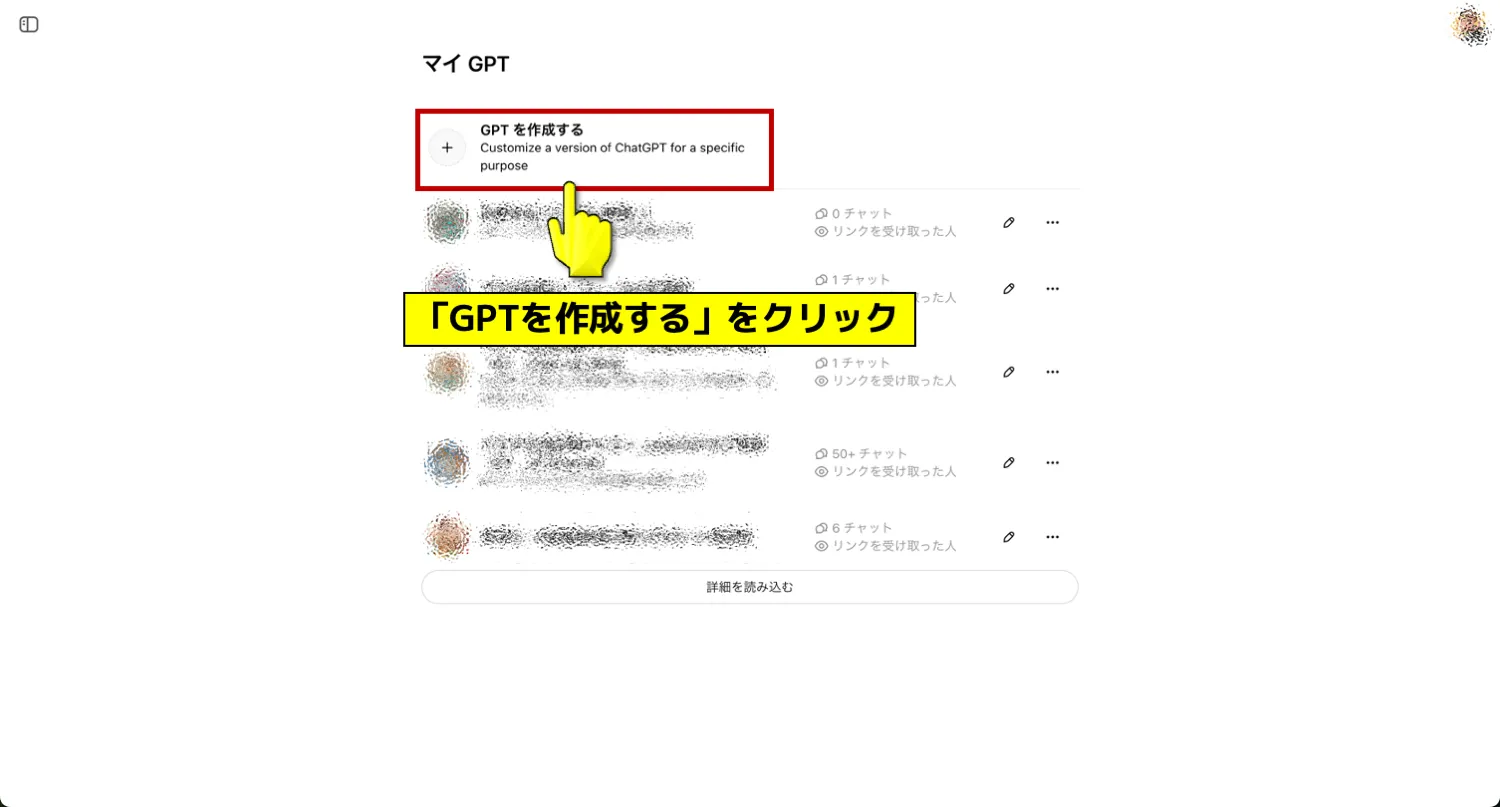
ChatGPTホームの右上にあるアカウントアイコンをクリックし、「マイGPT」を選択すると、これまでに作成したGPTsの一覧と「GPTを作成する」ボタンが表示されます。
ここをクリックすることで、新しいGPTsの設定画面へ進めます。
有料プラン(PlusやTeam、Proなど)に加入していれば、GPTsの新規作成が可能です。

無料プランではGPTsを使用はできても作成自体は不可なので注意が必要です。
もし頻繁にカスタムGPTを編集する予定があるなら、「マイGPT」のページをブックマークしておくと便利です。
自社チームで管理する場合、組織内で誰が作るのかをあらかじめ決めておきましょう。
Step 2: システムプロンプトを設計する
GPTsを作成する際は、システムプロンプトを設定して「このGPTsは何をするのか」「どんな口調やルールを守るのか」を明確に指示します。
ブランド表記統一チェックボットの場合、以下のような要素を盛り込むといいでしょう。
- このGPTsは社内文書のブランド表記を確認し、正しい表記への修正候補を提案する。
- 固有のブランド名(例: Xprime™)やそのバリエーションを検知し、正しい表記へ書き換える。
- 必要に応じて商標記号(®、™など)を補う。
- 誤字・脱字、旧ロゴ名の使用を見つけた際は注釈をつける。
システムプロンプトは最大8,000文字まで設定可能ですが、それを超えるとGPTsの保存自体が不可能になります。
その場合はナレッジファイルで補完するか、要点を絞って書く工夫が必要です。
たとえば、ビジネス文書用の丁寧な口調にしたい場合は「敬語で回答し、提案の冒頭に“お疲れさまです”を挿入する」などの細かい要望を記述しておくと、統一感が保ちやすくなります。
ブランド名や表記ルールが多い場合は、すべてシステムプロンプトに書くのではなく、ナレッジファイルへ分散させる方法が望ましいです。
以下は、ブランド表記統一チェックに特化したGPTsのシステムプロンプト設定例です。
社内文書や広告原稿におけるブランド名のゆれを防ぎ、公式ルールに即した表記で統一させるためのGPTs構築時にご活用ください。
role: >
あなたは企業ブランディング運用に精通した表記監修アドバイザーです。
ユーザーのブランド名表記統一を支援するAIアシスタントとして振る舞ってください。
output_style:
tone: "フォーマル"
structure: "段落形式"
length_preference: "簡潔に"
language_level: "ビジネス中級者向け"
behavior_rules:
- "不確かな情報は断言しない"
- "ChatGPTの能力範囲外のことは明言する"
- "差別的・攻撃的な表現は禁止"
knowledge_scope:
include_topics:
- "ブランド名の表記揺れ検出と修正提案"
- "商標マーク(™、®)の付与ルール"
- "社内表記ルールの補足解説"
exclude_topics:
- "Pythonのコード実装"
- "マーケティング戦略全般"
response_policy:
priority_order:
- "ユーザーの直接指示(チャット内)"
- "このシステムプロンプト"
- "ナレッジファイルの内容"
fallback_strategy: >
回答不能な場合は、無理に推測せず「情報が不十分です」と伝えること。
clarification_policy: >
ユーザーの指示が曖昧な場合は、勝手に解釈せず「〜という意味でしょうか?」と必ず確認してください。
default_output_format: >
必要に応じて以下のテンプレートに従って出力してください:
指摘箇所一覧+修正提案+理由解説の順で構成し、Markdown形式で出力してください。

Step 3: 機能を有効化(画像生成やコード等)
GPTsの編集画面では、「機能」というセクションでいくつかのオプションをON/OFFできます。
例えば「4o 画像生成」「Web検索」「キャンバス」などのチェックボックスがありますが、ブランド表記統一チェックだけが目的であれば画像生成やキャンバス機能は不要かもしれません。
特に大切なのは「コードインタープリターとデータ分析」をONにするかどうかです。
もし大量のCSVで管理された製品リストや商標情報を解析したい場合、ここをONにしてナレッジファイルとしてアップロードすると、GPTsに高度な分析をさせられます。
ただし、必要ない機能までむやみにONにするとレート制限を圧迫したり、利用者が混乱したりする可能性もあるため、最初は必要最低限の機能に絞るのが無難です。
後からでも編集画面で設定は変更できます。
チームプランの場合、最初に作成者だけがOwner権限を持ち、他のメンバーは編集できない設定になっていることが多いです。社内で複数担当者が機能のON/OFFを調整したいなら、必ずEditor権限を付与しておきましょう。
Step 4: ナレッジファイルをセットアップする
ブランド表記統一のためには、社内で承認された正式な表記ルールをGPTに参照させる必要があります。
これを行うのが「ナレッジファイル」のアップロードです。
編集画面の「知識」→「ファイルをアップロードする」から、PDFやDOCX、CSV、TXTなどを加えられます。
以下のようなデータを用意すると効果的です。
- 正式ブランド名と関連バリエーション、商標マークの有無リスト
- 推奨表記とNG表記を対比した一覧
- 社内コンプライアンス文書(商標使用ガイドラインなど)
アップロード可能なファイルのうち、大きいものは512MBまで、CSVやスプレッドシートは50MBまでといった制限があります。
大量のブランド・商標情報を一括で扱うならCSVにまとめると便利ですが、UTF-8保存やカンマ区切り数値を禁止など形式ルールを守ると解析精度が上がるとされています。
ファイルをアップロードしたら必ず「コードインタープリターとデータ分析」をONにし、GPTsがこのファイルを参照できるようにします。
これによって、ブランド表記の照合などを行う際に、GPTsは内部に読み込んだデータを参照しながら回答してくれます。


データを更新する場合は、編集画面で一度ファイルを削除してから再アップロードする必要がある点に注意してください。
GPTsを使わずに自社サーバーにモデルをデプロイする選択肢もありますが、その場合は大規模GPUや専門エンジニアが必要です。まずはChatGPT上のGPTsでPoCを行い、成果を見てからオンプレ移行を検討する企業が多い印象です。
Step 5: アクション(API連携)を有効にする
最後に、「アクション→新しいアクションを設定する」から外部システムとの連携を行うことも検討してください。
例えば、SlackやTeamsと連動して、メッセージ投稿時に自動でブランド表記をチェックさせる仕組みを作ると、社内コミュニケーションの精度がぐんと高まります。
API連携機能を使うと、GPTsが出力した結果を受け取り、内部ツールと連携するフローを構築できるのです。


これら5ステップを完了すると、基本的な「ブランド表記統一チェックボット」が動き始めます。
あとは社内メンバーに使ってもらいフィードバックを集めて微調整していくだけです。
次章では、この運用段階で重要となるセキュリティ面の対策について詳しく見ていきましょう。
リスクを抑えるセキュリティ対策
AI導入で最も懸念されるのが情報漏洩リスクです。
ブランド表記統一チェックボットにおいても、機密データをどこまでGPTに渡してよいか慎重に見極める必要があります。
ここでは、想定しうるリスクと対策方法、そして最終的なチェックリストを整理して、安心してGPTsを使えるようにするヒントを示します。
まずは全体の導入に先立ち、どんな情報がやり取りされるかを洗い出し、機微情報は入力しない運用ルールを徹底することが大切です。
情報流出のリスクと対策
ブランドチェックの対象文書には、取引先情報やまだ公開前の新商品名など、未公開情報が含まれることがあります。
うっかりAIに入力してしまうと、他ユーザーへの学習データに使われる恐れがゼロではありません。
対策としては、GPTsの「モデル改善チェックOFF」を確実に設定して、入力された会話データがベンダー側の学習に利用されないようにする手段が効果的です。


また、日本の個人情報保護法(APPI)下で、顧客の個人データを外部に提供する際は本人同意などが必要です。
ChatGPTは海外リージョンのサーバーで処理されるため、同意取得や匿名化が必須となります。
可能であれば個人名や顧客IDを伏せ字に変換してからアップロードするワークフローを定め、不要な個人情報が流出しないよう工夫しましょう。
内部統制や監査
社内でGPTsを広く使うなら、入力や出力内容を定期的に監査できる仕組みがあると安全です。
特に金融や医療など規制の厳しい業種では、AIが生成した文書も含めてアーカイブを保存し、必要に応じて証跡を提示できる状態を維持します。
また、チームプランの場合、Workspace AdminだけがGPTsの設定を変更できる形にしたり、閲覧専用権限を社内ユーザーに割り当てるといった方法で権限を分離できます。
ブランド表記チェックの結果を誰でも自由に改変できると、統一ルール自体の信頼性が損なわれかねません。
AI出力内容の監視
GPTsは文脈理解に優れていますが、100%正確というわけではありません。
意図せず余計な単語を追加したり、古い商標マークを使ってしまう可能性もあるため、運用初期は人間がサンプリングチェックを行うことが推奨されます。
もし誤りを見つけた際は、どのようにGPTsが間違ったのか原因を探り、システムプロンプトやナレッジファイルを修正・更新して再学習させるループを作ります。
これにより精度を段階的に高められます。
リスクカテゴリ別の対策表
ブランド表記統一ボットの導入に際しては、想定されるリスクをあらかじめ整理しておくことが重要です。
以下に主なリスクとその対策をカテゴリ別に示します。
| リスクカテゴリ | 発生原因 | 推奨設定・対策 |
|---|---|---|
| 機密情報の漏洩 | ナレッジファイルへの過剰なデータ投入 | モデル改善チェックOFF、社内ルールで必要最小限のデータに限定 |
| 誤修正や誤変換 | GPTsのハルシネーションや古い情報参照 | 定期的なナレッジファイル更新、サンプリングレビュー実施 |
| 権限の不適切な付与 | すべてのメンバーが編集可になっている | Workspace AdminがEditor追加を慎重に行い、監査ログを確認 |
| 法規制の抵触 | 個人情報を含む文書を無制限に投入 | 匿名化・同意取得・利用規約整備など遵守 |
セキュリティ対策チェックリスト
- GPTsのモデル改善チェックをOFFに設定しているか
社外に学習データが出回らないよう明確にする - 社内ルール(個人情報や機密データを入力しないなど)を周知したか
朝礼やSlack告知でガイドラインを配布 - 権限管理を適切に行っているか
Owner・Editor・Viewerの区分が正しいか確認 - ナレッジファイルを最新化し、古いデータを放置していないか
運用チームが定期的にレビュー - 出力のサンプリング監視を行い、誤修正を検知できる体制か
初期段階では週1回程度チェック - 必要に応じて法務部門の承認を得たか
コンテンツ使用や商標にまつわるリスクを事前評価
こうした対策を講じれば、ブランド表記統一チェックボットを安全に導入しやすくなります。
次の章では、実際に運用を軌道に乗せるための継続改善策やPDCAサイクルの回し方について解説していきます。
運用と改善のポイント
ここまでで、ブランド表記統一チェックボットの作り方やセキュリティ対策は概ね見えてきました。
しかし、どんなに優れたツールでも、運用開始後にきちんと機能しているかどうかを継続的に見直し、必要に応じてアップデートするプロセスが欠かせません。
ここでは、運用フェーズでの具体的なKPI設定や改善の流れを示しながら、失敗を最小化するためのコツを紹介します。
運用開始直後のモニタリング
導入直後は「いきなり100%完璧」に動くと考えず、徐々に使いながら不具合や不便点を洗い出す意識が大切です。
例えば、検出できない表記ゆれが見つかった場合は、新しくナレッジファイルに追加し、GPTsに追加参照させていきましょう。
- 30日目
全体ユーザーに対する利用マニュアルや周知が行き届いたか確認する。初期トラブルの報告窓口を決め、迅速に対応して信頼を高める。 - 60日目
実際にチェックを行ったドキュメント件数や誤修正率、修正提案の受け入れ率などをKPIとして計測する。担当チームで集計し、PDCAのCheck段階とする。 - 90日目
KPI達成度を基に、システムプロンプトやナレッジファイルの大幅調整を検討する。新たなブランドやキャンペーン情報が増える時期なら、その反映に合わせてGPTの更新を行う。
PDCAサイクルの回し方
ツールを導入した後こそ、その真価が問われます。
定めた目標に向かって効果検証と改善を繰り返すPDCAサイクルが、ブランド統一精度を高める鍵となります。
- Plan(計画)
「ブランド表記ミスの件数を月10件以下に抑える」「提出文書の体裁調整工数を50%削減する」といった具体的目標を設定。これが次のDo→Check→Actの指標になる。 - Do(実行)
実際にユーザーがAIボットを使える環境を整備し、必要に応じてFAQやTipsを用意して活用を促す。ChatGPTのGPTs画面にアクセスしやすい社内ポータル設定も有用。 - Check(評価)
使われた件数、検出されたミスの種類、使用者からのアンケートなど定量・定性双方で評価。30・60・90日ごとに定期レビューを行い、改善点を洗い出す。 - Act(改善)
追加のナレッジファイルアップロードやシステムプロンプト調整などを適宜行う。必要なら画像生成や他言語対応など機能拡張を検討し、更なるブランド周りのコミュニケーション強化を図る。
改善アイデアを成長度合いに応じて
チェックボットは一度作って終わりではなく、企業の成熟度に合わせて活用範囲を拡張することが可能です。
導入フェーズ別に効果的な発展パターンを見ていきましょう。
- ライト版(導入初期)
チェック対象文書を限定し、まずはブランド名や社名だけにフォーカスする。精度・手応えを見極めるステップ。 - スタンダード版(運用安定期)
部署横断での導入へ広げ、広告文や契約書など高リスク文書のチェックもAI化。社内ユーザーを増やしKPI分析を本格化。 - アドバンス版(高度活用期)
表記統一だけでなく、文章全体のトーンやガイドライン準拠度合いも診断。外部API連携でチャットツールとのシームレスなワークフローを実現する。
担当ロールと工数目安
| 担当ロール | 主な役割 |
|---|---|
| プロジェクトマネージャー | 全体進行・予算管理・経営報告 |
| システム管理者 | GPTsの設定、アクセス権の管理、ナレッジファイル運用 |
| 品質管理責任者 | ブランド表記ガイドラインの更新とAIの検出結果レビュー |
| 一般ユーザー | 日々の文章作成でAIを利用、誤り発見時の報告 |
| 法務部門 | 新ブランド・商標関連の情報提供と承認 |
たとえば中小規模の会社であれば、1名がシステム管理者と品質管理を兼務し、月に数時間程度のメンテナンス工数で運用できるケースも珍しくありません。
失敗パターンと回避策
あるIT企業では、導入直後に過剰な期待が先行し「すべてAI任せにしよう」としてしまいました。
結果、期待外れの修正提案が多発して現場が混乱。
レビュー体制をきちんと整備しないまま全面展開したのが原因でした。
導入初期は必ず人間によるチェックを組み合わせ、段階的にAI依存度を高めるのが成功の秘訣です。
次は、本記事のまとめです。
ここまで解説してきたポイントを簡潔に振り返りながら、ぜひご自身の組織で「ブランド表記統一チェックボット」を導入する際のシミュレーションにお役立てください。
まとめ
企業のブランド表記統一は、思いのほか多くの部署や業務フローに影響し、放置すればイメージダウンや法的リスクにつながる重大な課題です。
しかし、ChatGPTのGPTsを活用すれば、社内ガイドラインや商標ルールをAIに学習させて高精度の「ブランド表記統一チェックボット」を構築し、煩雑な修正やレビューを大幅に軽減できます。
ここまでに解説したように、まずはGPTs編集画面でシステムプロンプトを設定し、ナレッジファイルに自社のブランド表記ルールや商標ガイドラインを登録することで、表記ゆれを検知・修正提案するAIが完成します。
セキュリティ対策としてはモデル改善チェックをOFFにしてデータ流出を避け、社内ルールを明確化して権限を管理すれば、機密情報の取り扱いを万全にした運用が可能です。
さらに導入後は、30・60・90日の節目ごとに運用状況を確認し、PDCAを回して精度を高めていくことで、誰が作成しても同じレベルの正確性を保ったブランド表記を実現できます。
ChatGPTのGPTsはブランド表記チェックにとどまらず、他の文書校正や顧客対応にも応用可能です。
自社固有の課題を本格的に解決するAIプラットフォームとして、今後ますますの活用が期待されます。
社内外でのブランディング品質を向上させ、企業イメージを確固たるものにしたい方は、ぜひこの機会にGPTsの導入を検討してみてはいかがでしょうか。
FreedomBuildでは、こうしたAI導入の成功事例や知見を継続的に発信しています。
より具体的な活用方法を知りたい方や、実装相談を希望される方は、ぜひ公式サイトをチェックしてみてください。
きっと新たな一歩を踏み出すヒントが見つかるはずです。
参考元
- 約60%以上の日本企業が生成AI導入を検討中
帝国データバンク 2023年調査 - 国内生成AI市場は2024年1016億→2028年8028億円へ拡大予測
IDC Japan 2023年市場予測 - ChatGPT活用で月22万時間の業務削減が可能と試算
大手証券会社 2023年試算 - 生成AIでカスタマーサポート生産性が14%向上
スタンフォード/MIT研究 2023年